
In this blog, I focus on explaining the calculations of “f” and “g” in word2vec C code:
else
{
// the resulting f is a kind of position
f = (f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2);
f = expTable[(int) f];
}
// 'g' is the gradient multiplied by the learning rate
double g = (1 - word.codeArr[i] - f) * alpha;
For “f”:
It uses a speed-up method to compute the sigmod function:
for (i = 0; i < EXP_TABLE_SIZE; i++) {
expTable[i] = exp((i / (real)EXP_TABLE_SIZE * 2 - 1) * MAX_EXP);
expTable[i] = expTable[i] / (expTable[i] + 1);
}
Actually, this solution is very simple to understand.

Easy to find that sigmoid(x) values almost keep unchanged when x is too large or too small. Let’s assume sigma(x)=1 when x>MAX_EXP, and sigma(x)=0 when x<-MAX_EXP. The code splits the range [-MAX_EXP, MAX_EXP] into EXP_TABLE_SIZE pieces. In each piece, we assume the sigma(x) values are the same.
So, in the initialization of expTable, when i=0, that equals to we choose the first piece, where original x=-MAX_EXP; similarly, when i=EXP_TABLE_SIZE-1, the last piece is selected.
Based on this conversion, each time when we get the raw “f” value, we only need to figure out which piece this value should be located. That is implemented by
f = (f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2);
Namely, each piece enjoys 


For g:
As my another blog: https://yinwenpeng.wordpress.com/2013/09/26/hierarchical-softmax-in-neural-network-language-model/ said, sigma(x) in hierarchical softmax is:![\sigma([n(w, j+1)=ch(n(w,j))]\cdot {v_{n(w,j)}^{'}}^Tv_{w_I})](https://s0.wp.com/latex.php?latex=%5Csigma%28%5Bn%28w%2C+j%2B1%29%3Dch%28n%28w%2Cj%29%29%5D%5Ccdot+%7Bv_%7Bn%28w%2Cj%29%7D%5E%7B%27%7D%7D%5ETv_%7Bw_I%7D%29&bg=ffffff&fg=000&s=0&c=20201002)
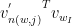

How to interpret above formular?
when code==1, 

We usually find the derivative of sigma(simi) after giving it a log(.). So, 

