
In traditional NNLM, we need to compute the conditional probabilities of all vocab words given a history: p(w|history) 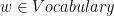
To solve the problem, some people like the authors of “A Scalable Hierarchical Distributed Language Model” proposed a solution named “hierarchical softmax” with following process:
1) first, build a Huffman tree based on word frequencies. As a result, each word is a leaf of that tree, and enjoys a path from the root to itself;
2) Now, each step in the search process from root to the target word is a normalization. For example, Root chooses left subtree with probability 0.7 and chooses right subtree with probability 0.3. This is a normalization step in this tree level. Naturally, the final probability for finding the target word is the continuous multiplication of probabilities in each search step. As the classic sentence in the page 2 says: “In probabilistic terms, one N-way normalization is replaced by a sequence of O(logN) local (binary) normalizations.“
Apparently, the time complexity decreases from O(V) to O(logV).
Luckly, the famous paper “Distributed Representations of Words and Phrases and their Compositionality” by Mikolov et al., gives concrete formula (i.e., Equ. 3)to compute the Hierarchical Softmax probability:
![p(w|w_I)=\prod\limits_{j=1}^{L(w)-1}\sigma([n(w, j+1)=ch(n(w,j))]\cdot {v_{n(w,j)}^{'}}^Tv_{w_I})](https://s0.wp.com/latex.php?latex=p%28w%7Cw_I%29%3D%5Cprod%5Climits_%7Bj%3D1%7D%5E%7BL%28w%29-1%7D%5Csigma%28%5Bn%28w%2C+j%2B1%29%3Dch%28n%28w%2Cj%29%29%5D%5Ccdot+%7Bv_%7Bn%28w%2Cj%29%7D%5E%7B%27%7D%7D%5ETv_%7Bw_I%7D%29&bg=ffffff&fg=000&s=0&c=20201002)
Now, I give some comments to understand this formula:
1)The whole process is a continuous multiplication. Product 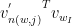
2) Given “similarity” score, Hierarchical Softmax converts it to two probabilities to search left subtree and right subtree. That’s achieved by using ![\sigma([n(w, j+1)=ch(n(w,j))]\cdot {v_{n(w,j)}^{'}}^Tv_{w_I})](https://s0.wp.com/latex.php?latex=%5Csigma%28%5Bn%28w%2C+j%2B1%29%3Dch%28n%28w%2Cj%29%29%5D%5Ccdot+%7Bv_%7Bn%28w%2Cj%29%7D%5E%7B%27%7D%7D%5ETv_%7Bw_I%7D%29&bg=ffffff&fg=000&s=0&c=20201002)
![[\cdot]](https://s0.wp.com/latex.php?latex=%5B%5Ccdot%5D&bg=ffffff&fg=000&s=0&c=20201002)


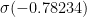
3) Now, we know how to compute the probability of ancestor j choosing j+1 (

貌似看你这篇文章,就有些理解Hierarchical Softmax了,一直很疑惑这个。
That’s my great honour ! I will modify it recently with more details.
请问sigma是什么函数?
hello, you can find the answer in my another blog: https://yinwenpeng.wordpress.com/2013/09/27/sigmoidlogistic-function-vs-softmax/
Thanks !!! You save my day !!!
haha, my great pleasure
Pingback: word2vec gradient calculation | Wenpeng Yin's Blog
thx for the article!
how are the embeddings for the ancestors trained though?
in practical, the context words and target words have separate embedding matrices.
Thanks for this explanation.
You say that it is for reducing computation cost. But if the classification problem has a hierarchical structure, (like there are subclasses of classes), then isnt it more appropriate to use this hierarchical softmax instead of the usual one? This looks like an other advantage, in addition to computational advantage. What do you think?
yes, I agree you argument. But for general language modeling, words do not have hierarchical classes, or it is pretty expensive to build hierarchical class structure for vocab before training the language modeling. So, some work like word2vec used huffman tree based on word frequency (which costs nothing to build) to denote the hierachichy. Indeed for other tasks in which hierarchical structure is important and less expensive, hierarchical softmax is obsolutely preferred.